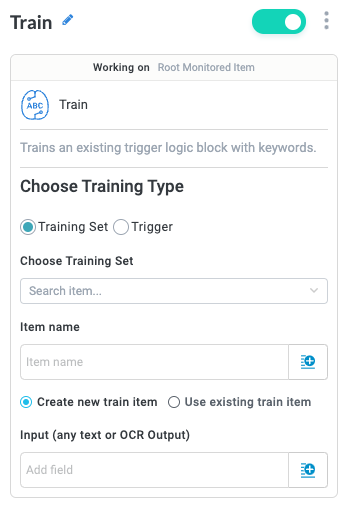
Train
The Train action allows you to leverage Tonkean machine learning, either adding items to an existing training set or adding training logic (either positive or negative examples) to an existing Text Analysis branch, improving its accuracy. This action can also be used to handle exceptions, such as in cases where an item doesn't process as expected and may require a new training set model to accommodate it.
Best Practices
To get the most out of this action, there are several best practices we recommend:
A good place to incorporate the Train action is following a failed match by either a Text Analysis (NLP) action block or a Text Extraction action block. You can combine this with an Ask a Question action that asks a process contributor what should have been extracted to ensure it's caught in future workflow runs.
The Train action is a great way to generate training sets. Rather than manually importing or creating files, you can use the Train action to generate realistic training data directly in the module.
You can train branches dynamically by using an expression in your train action. By using an expression, you can match to the appropriate branch to add the example to. There are various ways you can configure the expression, such as by asking a user for specific information or by setting it manually in the module.
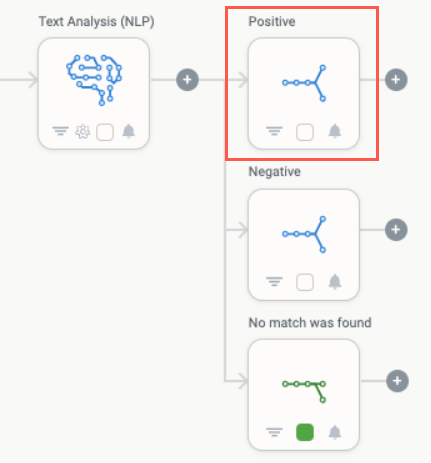
If you're selecting the trigger or branch using an expression, it must match the name of the branch. Notice in the example below the Train action titled "Positive". The expression used to select this action must therefore be named "Positive", not "Text Analysis (NLP) - Positive". For this reason, your branches should always have a unique, descriptive name.
Common Use Cases
The Train action often plays a supporting role in workflows leveraging the Text Analysis action. For example, in workflows that monitor and triage messages coming into an email inbox, the Train action is used when there is no match found by the NLP function. In this position, the Train action helps reinforce and improve the NLP of the module.
Configuration
The configuration for each section in the action panel is detailed below.
Choose Training Type
You can use the Train action to train both text extraction (OCR) models and text analysis (NLP) models. Select the training type for the Train block:

Training Set
This option allows you to add specified text to an existing training set.
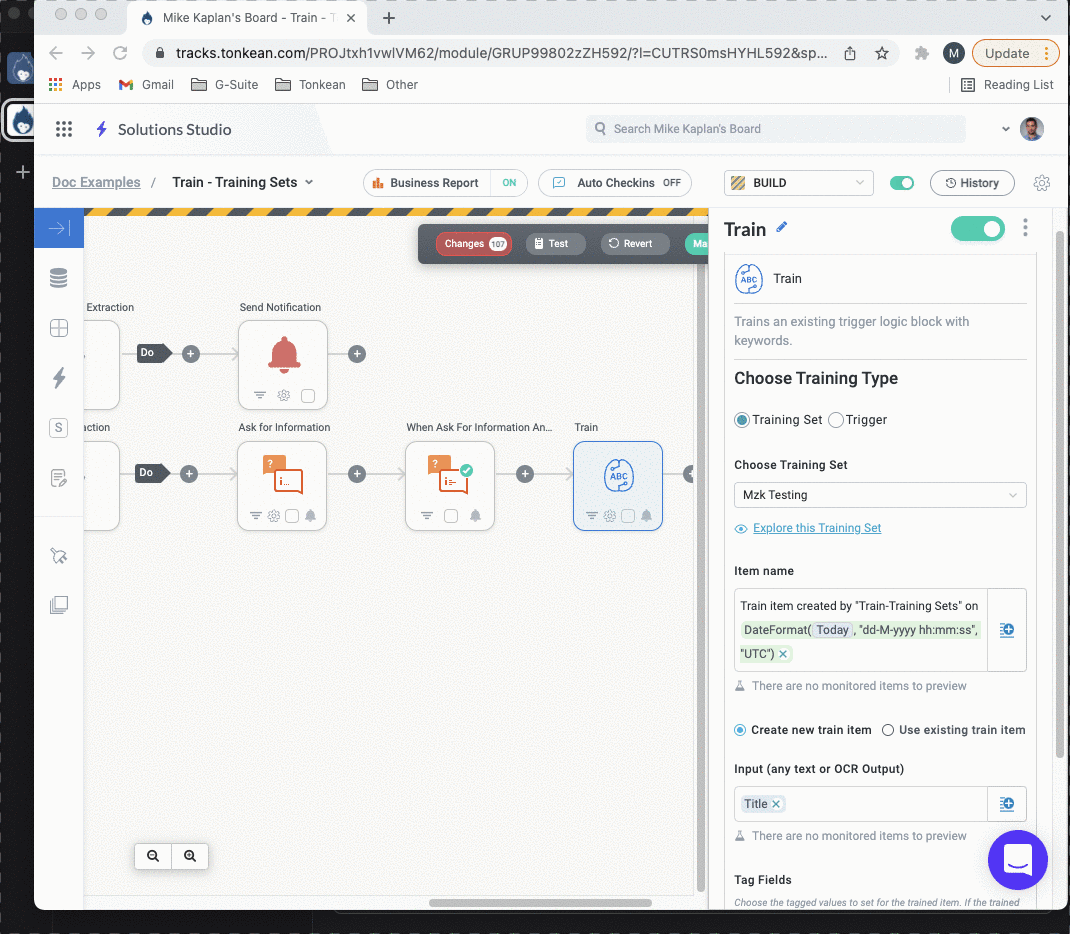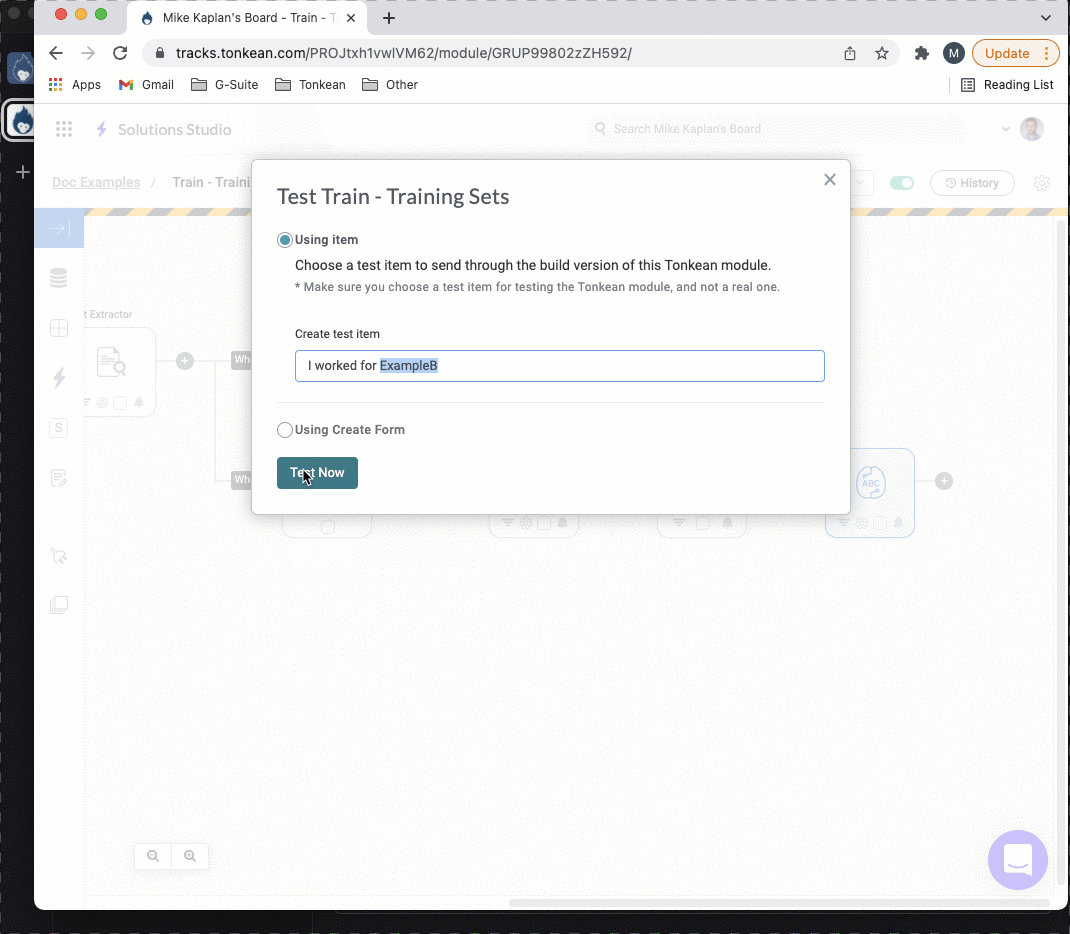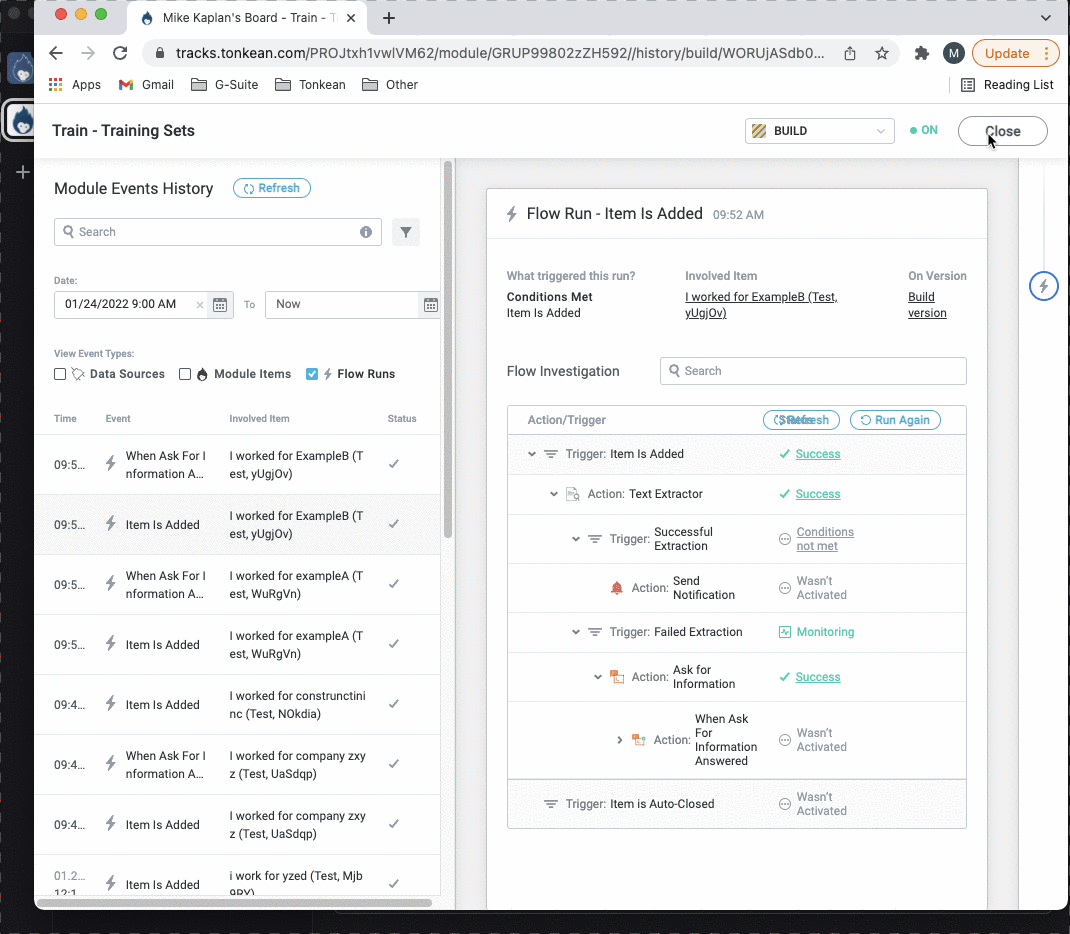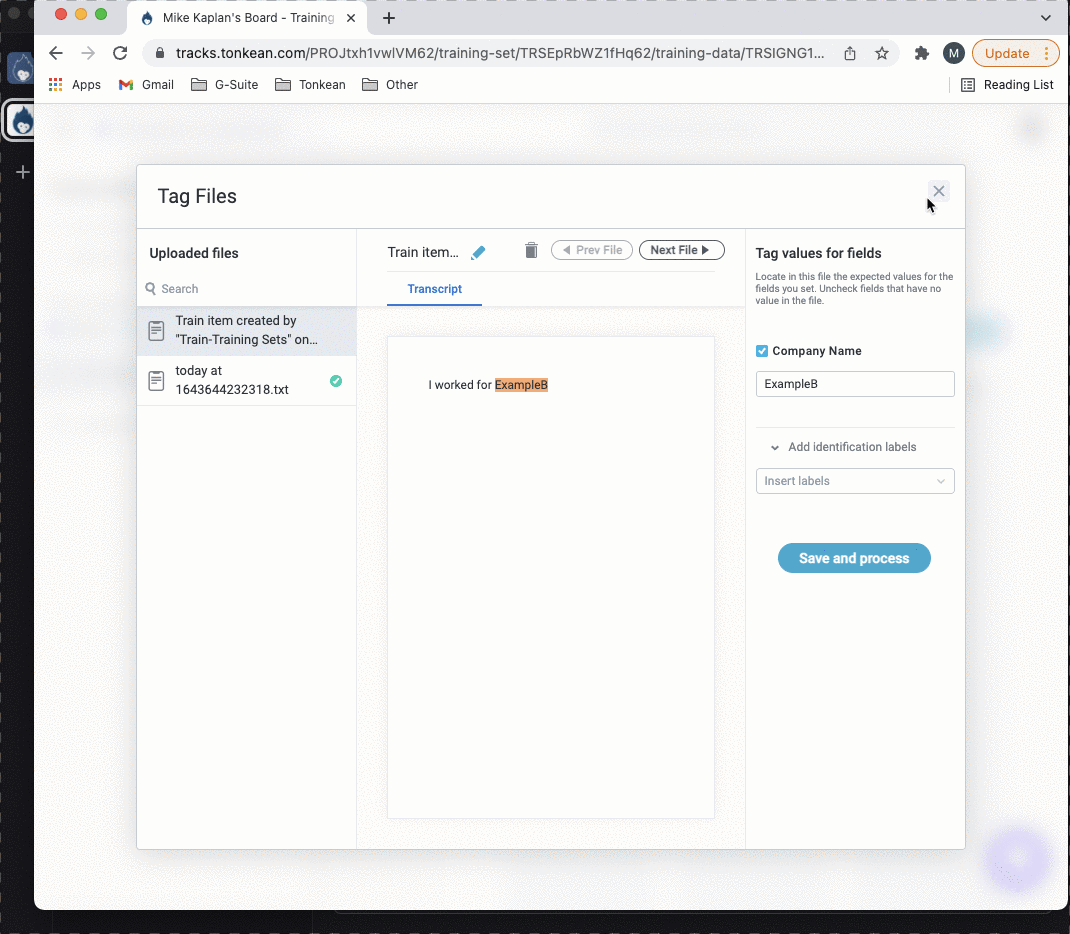
Choose Training Set
Select which text extraction training set you want to add the item to.
Training sets must already exist to appear in this dropdown. For more information about creating and managing training sets, see Create and Manage Training Sets.

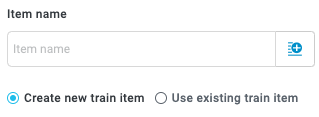
Item Name
When adding an item to a training set, you have the option of creating a new item or overwriting an existing item:
Create new train item - Create a new item. Enter a unique name for the item or select the insert field button,
 , to select from all available fields and insert it in the Item name field.
, to select from all available fields and insert it in the Item name field.Use existing train item - Overwrite an item that already exists in the training set. Enter the exact name of the existing item to overwrite this item.
Input
Enter the text, or select the insert field button, , to choose from all available fields, to send to the training set, where the text fields are extracted. This field is equivalent to the text or file manually uploaded when adding new training data files.
This option is only available if you select Create new train item below the Item name field. If you select Use existing train item, the training set processes the overwritten version of that existing item.

Trigger
In addition to leveraging an existing training set, you can select to train a trigger, which allows you to add keywords and examples to an existing Text Analysis branch, further improving its accuracy in your workflow.
The Choose Training Type options refers to training triggers, which may seem confusing considering you're actually adding logic to a branch block that doesn't initially look like a trigger. However, because of the way text analysis works in relation to the logic that follows, these branch blocks are triggers. They behave like "when" statements much like other triggers, allowing the following workflow to continue when the right conditions are met—in this case, whether the right keywords are found.

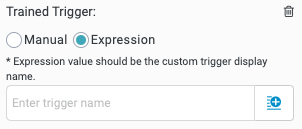
Trained Trigger
Manual (default) - Manually select the branch to add keywords to.
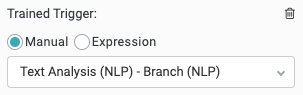
Expression - Enter an expression to select a dynamic custom trigger display name.
Examples
Training examples leverage Tonkean machine learning to teach the matching algorithm what words or phrases constitute a match or which ones don't.
Define the words and phrases, separated by a comma, that activate the workflow that follows the branch block.
You can also select the insert field button, , to choose from all available fields. This option can be useful if you want to use keywords that change as the workflow moves through its process.
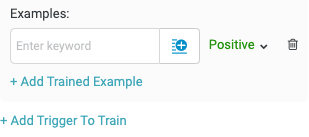
Select + Add Traing Example to include addition examples, marked as either Positive or Negative examples. Select + Add Trigger to Train to add keywords and examples to another existing branch block.