OpenAI
OpenAI is an artificial intelligence (AI) research laboratory that combines machine learning algorithms with deep learning techniques to create powerful AI models. Leverage these models for a wide range of tasks involving understanding or generating natural language, code, or even images. You can incorporate any of OpenAI’s models in your Tonkean solution, or even customize a model for your specific needs.
Authenticate with OpenAI
To use OpenAI models in Tonkean, you must first connect OpenAI as a data source:
Select the main nav icon,
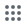 , in the upper left and select Enterprise Components. The Enterprise Components screen displays.
, in the upper left and select Enterprise Components. The Enterprise Components screen displays.Select + New Data Source in the upper right.
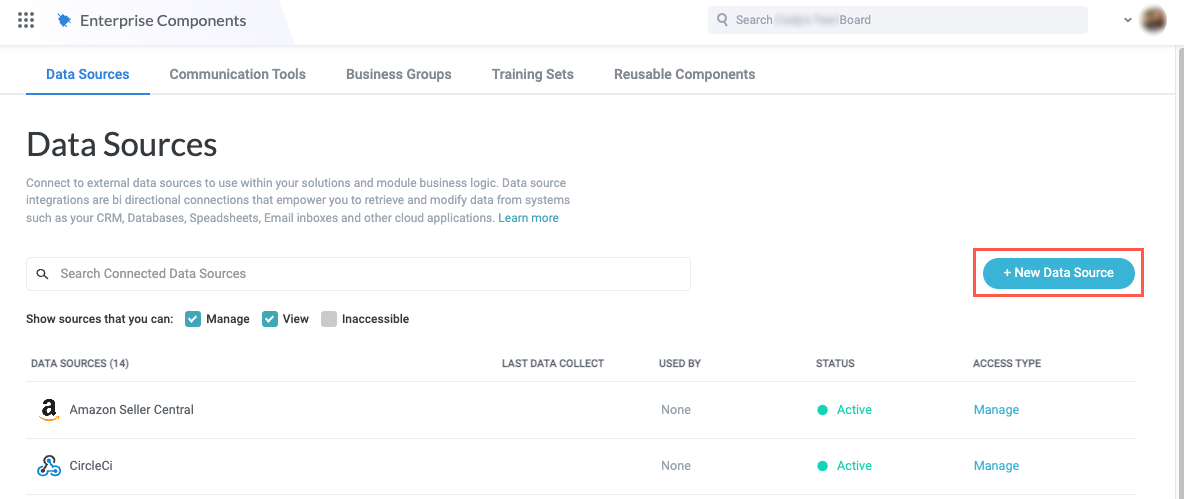
Select Cloud Application from the dropdown. The Add New Data Source window displays.
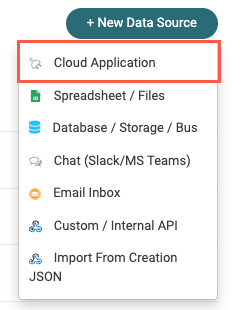
Enter "OpenAI" in the search field, then select OpenAI. The Set Up Integration window displays.
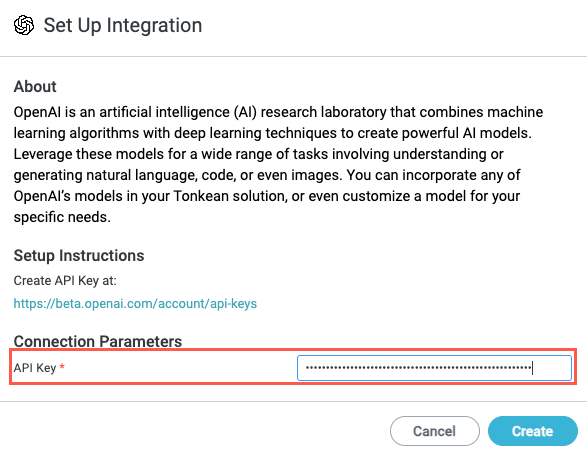
Retrieve your OpenAI API key and enter it into the API Key field, then select Create. The OpenAI data source configuration panel displays.
Your OpenAI account is connected to Tonkean as a data source. Be sure to provide the relevant solutions access to this data source so you can use it in your modules.
Use OpenAI Module Actions
There are a host of OpenAI data source actions you can use in your module workflow.
See the list of actions below for a brief description of each available action:
The Tonkean OpenAI data source uses the OpenAI API. For more information and technical details, see the OpenAI API Reference.
Some actions use endpoints that have been relegated to "legacy' status, meaning that OpenAI is no longer updating these endpoints and recommends transitioning to a newer alternative—actions using these legacy endpoints are indicated below. If your workflow is currently using these actions, there's no immediate need to update to the newer alternative, but you should plan to update in the future before these endpoints are deprecated.
Create Completion (Legacy) | Creates a response for the provided prompt and parameters. This is a simpler version of the Create Chat Completion action. Unless you're already using this action in your workflow, we recommend taking advantage of the additional parameters in the Create Chat Completion action. If the Temperature and Max Tokens fields are left empty, their values are set to |
Create Chat Completion | Creates a response for the given chat conversation. Compared to Create Completion, this action offers several additional fields, including the option to specify the assistant (the "role" the model should play). Additionally, you can provide the previous chat data to provide context for a follow-up request. If the Temperature and Max Tokens fields are left empty, their values are set to |
Create Vision Completion | Creates a completion for the provided prompt and image input. |
Create Moderation | Determines whether a text input is potentially harmful. Returns a series of content moderation categories and scores. |
Download | Retrieves the results of a batch processing job and generates the output as a JSONL file. |
Cancel a Batch | Cancels a batch processing job. |
Get Fine Tune Model ID | Retrieves information about a fine-tuning job. Returns all available data, including the current status, of a fine-tuning job. For more information about fine-tuning, see OpenAI's Fine-tuning documentation. |
Create a Batch | Creates and executes a batch from an uploaded file of requests. To create a batch, you must first upload a batch file using the Upload File action. |
Create Fine Tune | Creates a fine-tuning job that begins the process of creating a new model from a given data set. For more information about fine-tuning, see OpenAI's Fine-tuning documentation. |
Upload File | Upload a |
Helpful OpenAI and LLM Terms to Know
Understanding these actions and their configuration and attribute options can sometimes be difficult due to the terminology specific to large language models (LLMs). Below are several helpful terms to know:
Batch - A combined group of requests, processed by OpenAI models asynchronously. Batch processing is an option for users to submit a group of requests that are not time-sensitive in return for a 50% reduction in API usage costs. The turnaround time is 24 hours or less.
Batch requests are submitted in a JSONL file; responses are generated and returned in a separate JSONL file.
Completion - The most likely text to follow an input (the prompt, usually text or image). Generating completions is the main goal of language models like OpenAI's GPT-4. The model is given a prompt and the model's job is to generate the text that's most likely to follow the prompt—this "most likely" follow-up is the completion.
For example, you can enter a prompt like "The capital of Japan is" and the model will generate the completion "Tokyo." The same process works for questions. You can ask "Where do Tonkean monkeys live?" and the model will generate the completion "Indonesia."
When you use Create Completion actions in Tonkean, you're simply asking the model to provide an output based on your input.
Fine-tuning - Customizing a model for your particular usage or application. Fine-tuning can provide higher-quality results and lower latency through providing additional use case-specific training data. Fine-tuning can require significant time and effort, so it's generally recommended only after trying to engineer the best possible prompts first.
Prompt - The content input into a model to generate an output (a completion). A prompt is generally a set of instructions for the model or requests to complete certain tasks (for example, "Write a regular expression that validates email addresses"). Prompt engineering is the act of designing and optimizing prompts to achieve the best possible results.
Temperature - A scaled value that controls the variation or randomness of the model output. Temperature is a value between 0 and 2, where 0 returns the most deterministic, lowest variance output and 2 returns the least deterministic, highest variation output. A higher temperature can increase the likelihood of hallucinations, but can provide more interesting and creative completions. For business processes, we recommend starting with the default temperature of 0.7 or 1, depending on the model you're using, and decreasing it if you're receiving too many unexpected or strange results.
Token - The portion of text language models are designed to work with. Tokens can be a single word, a part of a word, or even a single character. Generally, the more complex a word, the more tokens it will be comprised of; simpler, more common words are often just a single token. Understanding tokens is mostly relevant when it comes to limits. The Create Chat Completion action, for example, allows you to limit the number of tokens in the response.